
Tento článek vyšel před 6 lety. Můžete si jej přečíst v rámci zkoumání minulosti, ale přepokládejte, že dnes se Honza již nemusí s obsahem ztotožňovat.
Utekl další týden (21.9. — 25.9.) a tak stejně jako minule sepisuji, co jsem dělal a co zajímavého jsem se naučil. Především se snažím rozvíjet junior.guru. Nemám šéfa, kterému bych reportoval každý svůj krok, ale mám podporovatele, a ty by mohlo zajímat, jestli se neflákám. Taky je to způsob, jak se sám doma nezbláznit a nepropadat pocitu, že je zase pátek a já jsem přitom nestihl nic udělat.

Byl prodloužený víkend a v pátek jsem programoval do večera, tak jsem si nakonec nechal psaní poznámek až na úterý ráno.
Stránka s nabídkami práce
Řazení
V minulých poznámkách jsem psal, že jsem konečně sjednotil nabídky přímo z JG a nabídky odjinud stažené robotem. Ale že se to řadí nesmyslně a musím to vylepšit. Tak jsem první půlku týdne věnoval tomu řazení a vytvořil skórovací systém, který bere v úvahu:
- Nějakou tu protekci pro inzeráty přímo z JG,
- stáří inzerátu a jejich měsíční obnovování,
- jejich juniornost podle skórovacího systému, který už jsem řešil dříve.
Lámal jsem si s tím hlavu a nakonec jsem si musel nechat poradit od kamaráda Míly, který má rád šifry, a od bráchy, který se matematiky nebojí tak jako já:
Mám seznam ponožek a ty mají nějaké navzájem nesouvisející vlastnosti:
- barvu
- datum uvedení na trh
- cenu
Chtěl bych je seřadit tak, aby byly řazeny vesměs podle ceny, ale černé ponožky by měly být trochu vejš a taky ty nejnovější, ty by měly dostat v tom řazení výhodu. Neměly by být černé a nové zákonitě první, ale prostě dostat výhodu. Když bude uuuuplne nova červená ponozka, chceš ji dat nějakou šanci, aby mohla prebit černou i levnou. Jak bys to řešil? Vážit umím, ale mám problem s tím, ze ty vlastnosti jsou hrušky a jabka a nevím, jak bych z nich udělal srovnatelná čísla.
Řešení je v tom, že si člověk musí ty čísla prostě převést na něco, co srovnat jde. Takže si je vynést na nějakou škálu a zařadit do hodnoty třeba 1 až 100 a potom to může vážit apod. Víc je o tom tady. Na mě je to větší než malé množství matematiky, ale dalo se to nakonec přežít.
Každopádně ač to zpočátku vypadalo dobře a mechanismus řazení je promakaný, když se na to už pár dní dívám, vůbec s tím spokojený nejsem :D Myslím, že to řazení pořád nedává smysl, takže možná to nakonec zase překopu a možná z toho nebudu dělat rocket science a prostě udělám .order_by() podle raz dva tři něčeho a bude to.
Odstranění emoji
Někteří inzerenti odjinud si zvyšovali pozornost k inzerátu skrze emoji a už delší dobu mě to tak nějak dráždilo. Hlavně pořád nějak nedůvěřuji emoji jako něčemu, co lze používat volně napříč platformami bez újmy na přístupnosti a čitelnosti. Takže jsem emoji odstranil. Naštěstí to bylo s balíčkem emoji jednodušší, než jsem čekal.
Loga firem
Chtěl jsem, aby v novém designu byly u inzerátů loga firem. Získat je z jiných zdrojů nebývá problém, ale nevěděl jsem, co s mými inzeráty na JG. To poslední, s čím jsem se chtěl teď trápit, je umožňovat někomu nahrávat logo k inzerátu, řešit velikost souborů, formáty a kdo ví co ještě. A to ani nezmiňuji, že inzeráty se stále zadávají pomocí Google Forms a celé JG je statický web.
Po pár dnech přemýšlení jsem ale dostal nápad, že bych mohl jako logo použít favicon! On totiž dnes favicon není jen taková ta mrňavá ikonka v prohlížeči, ale používá se různě na mobilech apod., takže hodně stránek přímo dává k dispozici přiměřeně velký čtvercový obrázek, v němž je v případě firemních stránek prakticky vždycky jejich logo nebo jiný "projev" brandu. Jako Jirka by mě asi zabil, ale nedá se nic dělat, startuppyčo, ideály jdou stranou. Firmy můžou být rády, že tam vůbec nějaké logo bude :D
Existuje knihovna favicon, která ze stránky všechny ikonky vydoluje. Zatím jsem ji použil, ale nevím, jestli jsem s ní plně spokojen. Jednak má v sobě zapečené requests, takže se to fackuje s asynchronním Scrapy, na kterém robot běží, jednak i ty ikonky hledá trochu divně, nicméně problém to zatím řeší. A výsledky jsou překvapivě dobré! Opravdu jsem nevěděl, jestli tahle strategie vůbec půjde použít, ale vypadá to, že jo. Pak už stačilo jen naučit se s Media Pipelines ve Scrapy a bylo to.
Ne, samozřejmě nebylo, protože každé logo má jiný tvar, formát, pozadí, no prostě je to svinčík. Naštěstí se tyhle věci dají udělat přes pillow a když si člověk udělá vlastní Media Pipeline, jde to dost snadno.
Ne, nejde to snadno. Půl dne jsem strávil s tím, že jsem nechápal, proč mi to nechce ořezat bílé nebo průhledné pozadí, i když celý internet tvrdí, že ty tři řádky kódu, co tam mám, prostě musí fungovat. Nakonec mě spasilo tohle. Některé obrázky mají alfa kanál, který zmate pillow. Je průhledný, ale pillow si myslí, že to je něco, co se ořezat nehodí. V souvislosti s tím, že jsem chtěl ořezat i bílou, jsem nakonec každý obrázek přeplácl na bílé pozadí, zcela zrušil alfa kanál a do obdélníku ořezal okolí, které bylo jen bílé. Pak z toho dělám ještě čtverec tak akorát pro výpis na stránce a je to.
Redesign nabídkových boxů
Teď už nebránilo nic tomu, abych mohl předělat boxy ve výpisu nabídek práce na něco hezčího. Nakreslil jsem si to na papír, promyslel a předělal. Za pár hodin jsem to měl v pátek po obědě hotové.
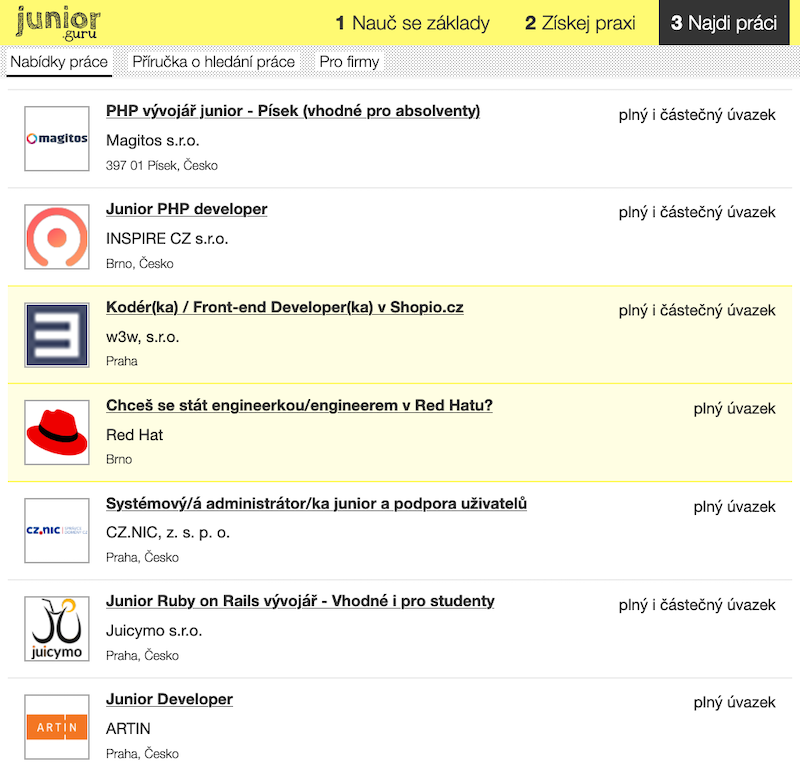
Díky logům firem to dost prokouklo. Pak jsem se rozhodl ještě pracovat na tom, aby se typy úvazků zobrazovaly jako štítky. Jenže jsem tam narazil na hodně podpovrchové práce a částečně i technického dluhu, takže jsem tuto věc čistil a předělával zbytek pátku a už nezbyl čas ani napsat poznámky. Design štítků je samozřejmě prozatimní a i na celém zbytku stránky hodlám dál pracovat.
Oprašování robota na nabídky práce odjinud
Všiml jsem si pár false positives/negatives při vyhodnocování nabídek, které zbytečně snižovaly skóre dobrým nabídkám, takže jsem pár takových věcí vyladil. Chtělo by to ale ideálně ladit nějak pravidelně nebo vymyslet nějaký monitoring, těch problémů je tam určitě víc, jen je to ladění časově náročné, tak se mu tolik nevěnuju.
Retries
Když intenzivně zapisuji do své SQLite databáze, někdy to selže kvůli tomu, že je databáze zamčená. Řešit to nejde, SQLite na intenzivní zápis není dělaná, takže to obcházím, protože mi jinak ve všem vyhovuje. Když zápis selže, zkouším to znovu. Jednak jsem do této mechaniky přidal exponential backoff, jednak jsem ji měl už na dvou místech, tak jsem ji trochu zobecnil a refaktoroval.
Chtěl jsem, aby čekání na zamčenou databázi nebylo blokující pro Scrapy (tzn. pro Twisted, na kterém je Scrapy postavené), ale nakonec jsem se do toho úplně zamotal a vzdal to. Nejblíž byla asi tato rada, ale vzhledem k tomu, že to i v této fázi funguje dostatečně (Scrapy pouštím paralelně v několika procesech, takže i když jeden zablokuji, ostatní by měly jet), nechtěl jsem tomu věnovat už víc času.
Monitoring
Robot sice funguje, ale někdy nefunguje dokonale, a já to potřebuji vědět. Je tedy pro mě velmi důležité vymyslet správně monitoring a hlavně správné limity na to, aby mi něco spadlo nebo poslalo notifikaci v případě, že se tomu mám věnovat a aspoň to zkontrolovat. Zase mi to nemůže posílat notifikace pořád, jinak vznikne notification fatigue, tzn. otupím a věnovat se tomu přestanu.
Zatím to nemám doladěné, ale aspoň jsem vyřešil ukládání statistik z každého scraperu nabídek do databáze. Díky tomu je mohu někde číst nebo na základě čísel shodit CI build. Například pokud jeden zdroj vyprodukuje nula nabídek práce, je to dost podezřelé.
Další poznámky
- Přidal jsem na seznam podporovatelů Mirka Svobodu! Díky!
- Prodloužil jsem za Pyvec doménu pyladies.cz.
- Prodloužil jsem možnost přispívání Pyveci skrz Benevity. Pokud pracujete pro nějakou americkou korporaci jako třeba Oracle, velmi pravděpodobně můžete přes Benevity přispívat na různé neziskovky a vaše firma k tomu nějaké peníze ještě přihodí. Výhoda je, že přijde třeba dvojnásobek peněz. Nevýhoda je, že peníze putují do nějakého Benevity UK a z něj potom i přijdou na účet neziskovce, takže si tento příspěvek nemůžete odečíst z daní jako např. u darujme.cz. To lze jen u darů, které směřují do českých neziskovek.
- Poslal jsem (myslím podruhé za existenci JG) přihlášku do LinkedIn Talent Solutions Partner, abych mohl používat jejich rozšířené API, ale moc od toho nečekám. Sice jsem už mohl napsat, že mám mezi klienty např. Red Hat, ale myslím, že mi stejně (zase?) ani neodepíšou.
- IFTTT mi napsalo, že už nebude zdarma nebo tak něco. Používám to jen jako RSS čtečku (viz How I consume content), takže se mi za to nic platit nechce. RSS feedy jsem z toho vytáhl a přemýšlel, kam s nimi. Integromat pořád ještě zadarmo je, tak jsem koukal, jestli to mohu přesunout tam. Jenže bych musel vytvořit scénář pro každý RSS feed. To jsem musel i předtím, ale v IFTTT to bylo na tři kliky. Nakonec jsem se rozhodl, že si seznam zdrojů uložím do souboru tady na blogu a dopíšu si Pelican plugin, který z toho vygeneruje jeden RSS feed. To je pro mě díky feedparser a tomu, že jsem takové věci už dělal, hodně jednoduché. Tento feed potom předhazuji Integromatu a ten mi vše nové posílá do Pocketu. Vyřešeno, snad to bude fungovat. Zároveň jsem smazal
comments.pya v Integromatu vypnul své řešení odkazů na komentáře, protože od září zrušili podporu pro Twitter a já byl líný to řešit. Ty odkazy nemají hodnotu toho času, co bych tím strávil.
A co vy?
Pokud byste čistě náhodou měli dojem, že jste oproti mě za uplynulý týden vůbec nic nestihli, tak mám pro vás skvělou zprávu! V klidu se na ten dojem můžete vykašlat. Není zač!
Co mě zaujalo
Když si něco přečtu nebo poslechnu a líbí se mi to, sdílím to na Pocketu. Od posledních poznámek jsem sdílel toto:
- Gravitace namísto vodíku. Automobilka Nikola přiznala, že její tahač nejel na palivo budoucnosti, ale jen z kopce
Jak se dneska dělá byznys - Lepší parkování
Cena za parkování. Už jsem to jednou četl, ale neuškodilo si to přečíst znova. - Prahou zapomenuté Ostravsko a Karvinsko může být skvělým místem k životu
Nejsme jen hornický bizár!!! - Chřipka, která zahubila víc lidí než obě světové války dohromady
Jedeme podle plánu z roku 1919 - Marketingový fail jménem USB aneb když se tvůrci nedohodnou na názvu ani konektoru
Tak už tomu zase rozumím o něco lépe. Teda vlastně nevím, možná tomu rozumím ještě méně :D - Placebo, které přišlo pozdě. Na rozdíl od jiných opatření ale eRouška 2.0 aspoň neškodí
Rozbor proč eRouška už asi nijak nepomůže - K čemu je Senát, lidé často neví. „Vysvětlujte a nezlobte se na ně, že se stydí zeptat,“ radí Petr Pithart
Co dělají senátoři? Kdo je váš senátor? K čemu vůbec senát je? - Nástroje státu je třeba začít využívat a nebát se, že nějaká korporace uteče, říká Stropnický současné levice pro městskou střední třídu a Zelených
- Covid-19 teď udeří s prudkou silou. Co může každý z nás dělat?
Návod na následující dny - Až nás půjdou miliony. Jak těžké je počítat účastníky demonstrací
Jak se počítají denonstranti - Banter bloguje: Příručka o hledání první práce v IT
Díky za recenzi a komentář! - Poslední zhasne. Babiš chtěl být státník, ale dopadlo to jako vždy
Četl jsem ten projev stejně. Sledování seriálu Borgen zásadně pomáhá vidět mezi řádky a uvědomovat si celé to divadlo za tím. - Which Scale?
Proč věci, které fungují Facebooku, nejsou dobré pro vás a proč to, co funguje vám, není dobré pro junior.guru - Korona – praktický průvodce pro začátečníky
Nakazit se nechcete
Vygenerováno pomocí pocket-recommendations.
